Bias and Fairness in Multimodal Emotion Recognition Across Cultures (2022) ¶

Members - Advait Rane, Nghi Le, Armaghan Asghar
This project aims to study and quantify the biases learned by emotion recognition models on the multi-modal cross-cultural SEWA dataset, and contribute a way to reduce biases in the models. We analyse the data to identify sources of bias the model may learn. We quantify bias and unfairness in the predictions of baseline deep learning emotion recognition models trained on different modalities. We further analyse the effects of late fusion on prediction bias and evaluate debiasing strategies at the late fusion step.
We followed the AVEC 2019 CES guidelines and extracted audiovisual features including Low Level Descriptors, Bag-of-words, and Deep Learning representations. We passed these features though a 2-layer LSTM regression model to predict arousal, valence and liking. We used 4 metrics to quantify fairness in the predictions from different features:
- Mean Difference
- CCC Difference
- MAE Difference
- JS Divergence
We also quantify the “culture predictivity” of different feature sets by training a 2-layer LSTM to predict the culture from the features. Finally, we explored Late Fusion Debiasing - debiasing by dropping the highly predictive feature sets at the late fusion step.
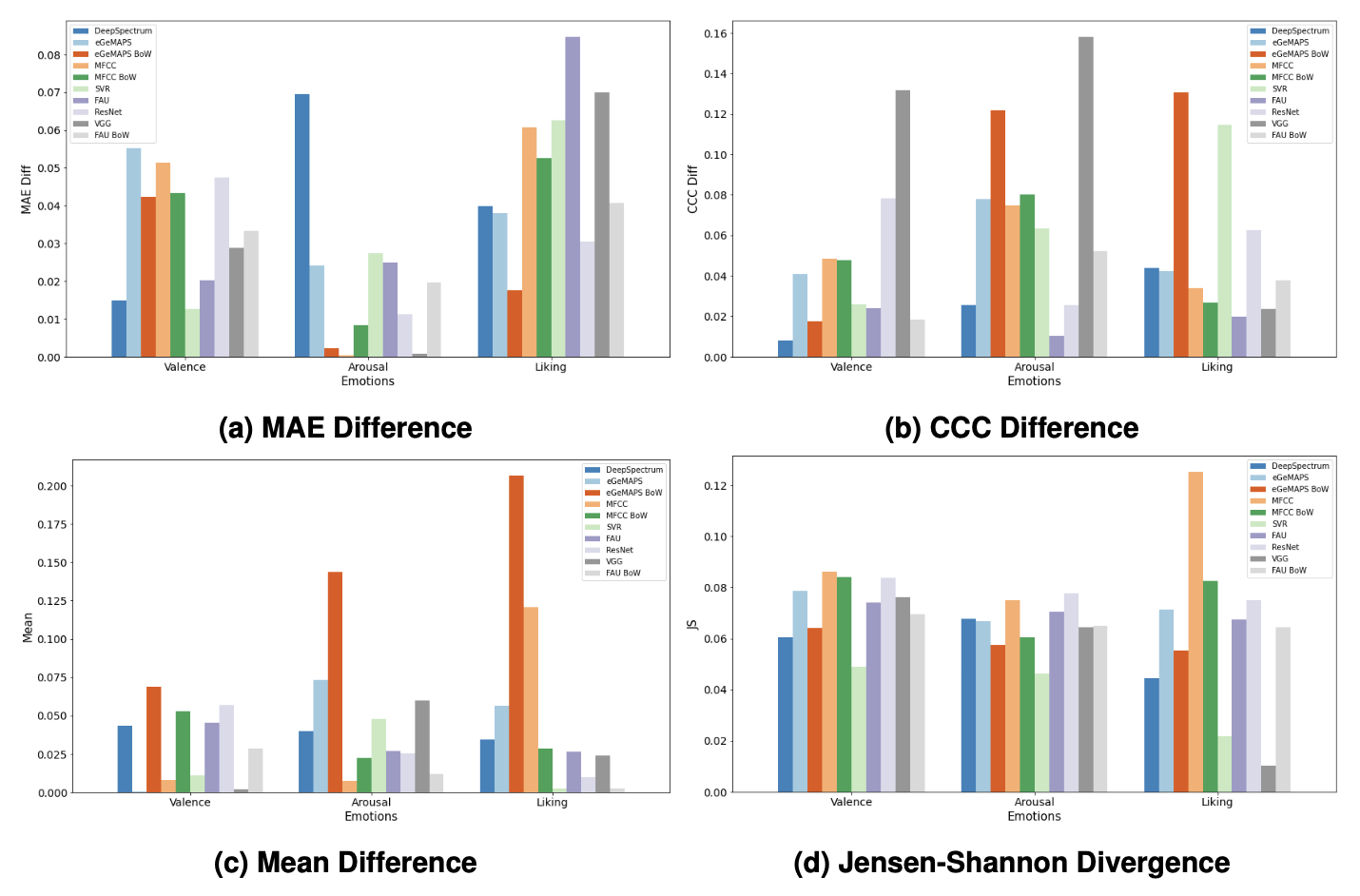
The results for the fairness metrics evaluated across different feature sets can be seen in the figure below. These results indicate that different features perform better on different metrics. When using these features for different applications, we should use those features that have the best performance on a metric suitable for that application.
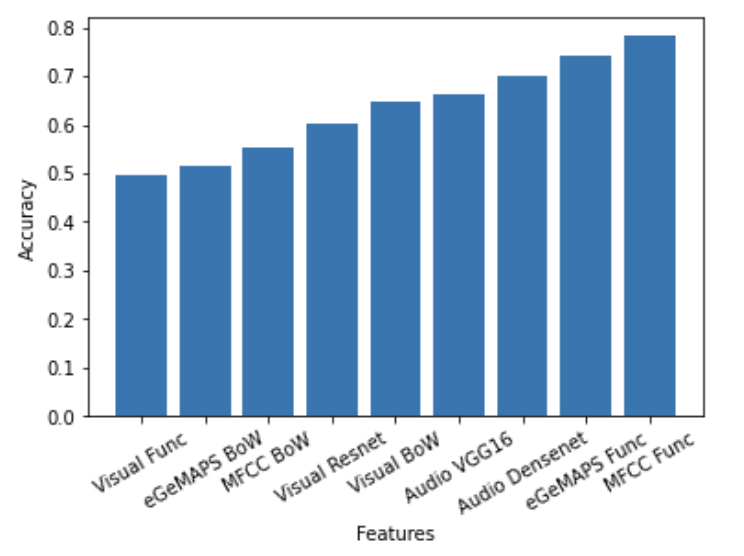
Our results for culture predictivity indicate that visual LLDs and Bag-of-Word features generally have the lowest culture predictivity and are better features to use to create a debiased emotion recognition model on this dataset.
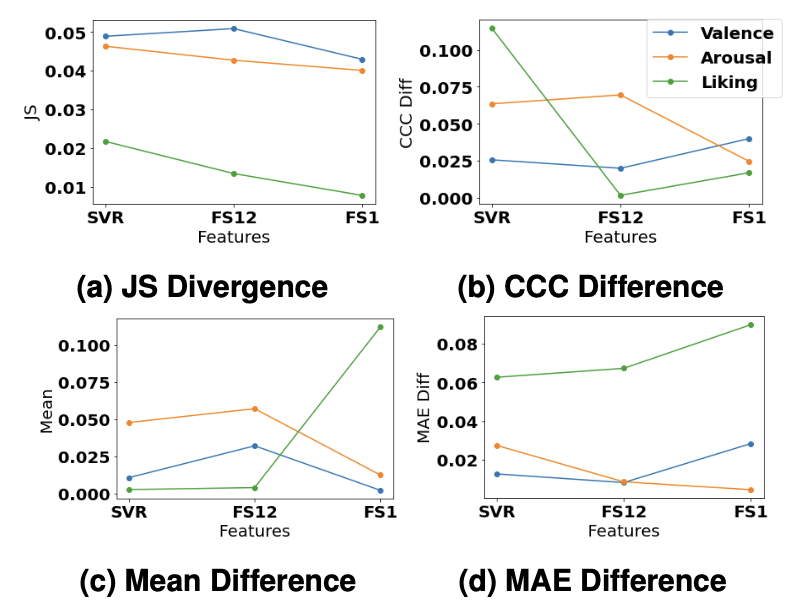
Lastly, the Late Fusion Debiasing results show that dropping highly predictive feature sets result in better performance on the fairness metrics, with the predictions being independent of an individual’s culture membership.
You can refer to the report for this project here for details.