Inherently Interpretable Prototype Bottleneck Models (2022) ¶
Members - Advait Rane, Nicholas Klein, Yang Cheng, Rajat Gupta
Inherently interpretable models provide explanations for their outcomes that are faithful to model computations. The Concept Bottleneck Model (CBM) and the Prototypical Parts Network (ProtoPNet) are two such models. We aim to improve the interpretability and data-efficiency of such models by augmenting them with auxiliary concept datasets. The Prototype Bottleneck Model (PBM) trains the bottleneck concept layer with auxilliary concept datasets and clustering objectives. Our methods resulted in a comparable classification performance with improved interpretability and data-efficiency while learning intuitive and faithful concepts.
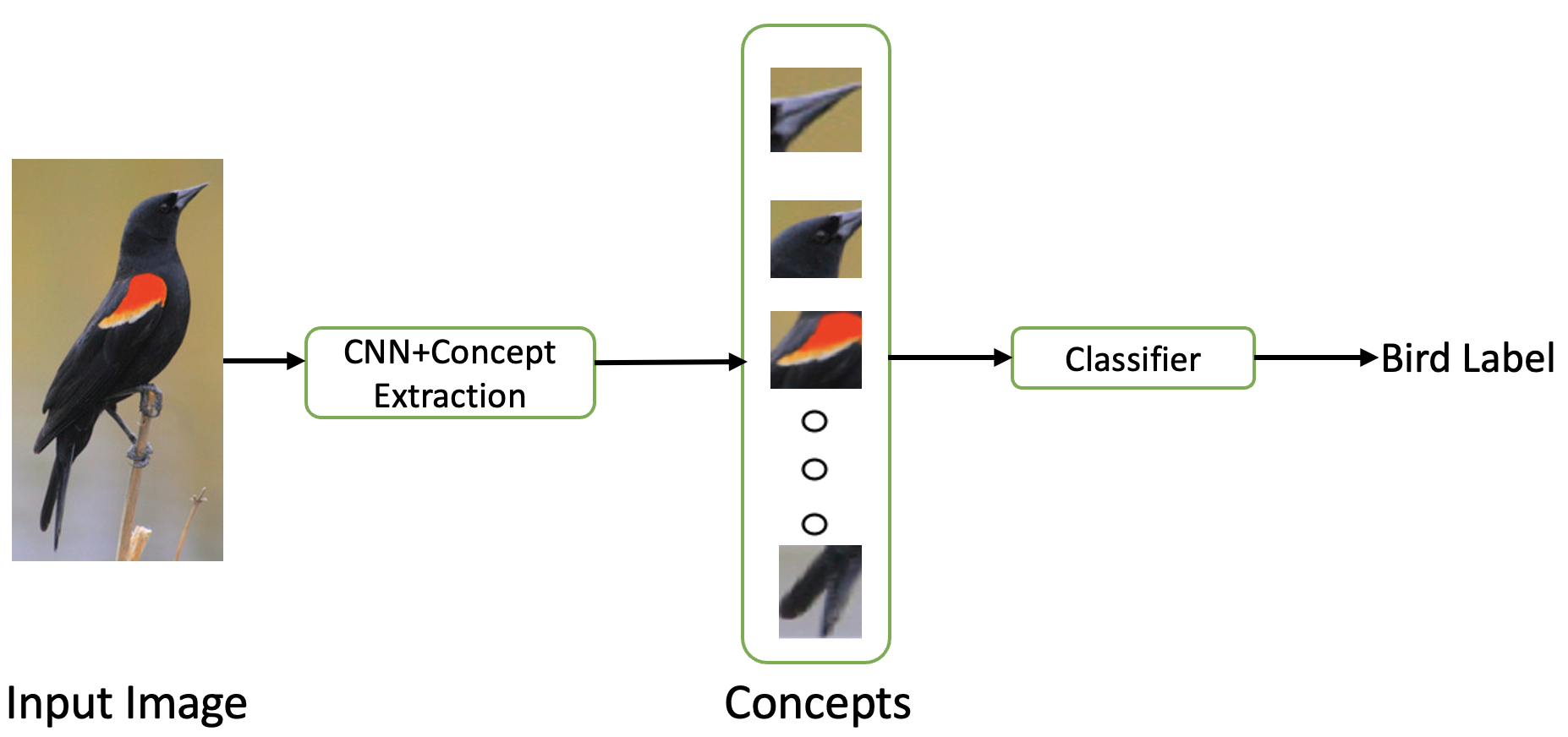
We modified the ProtoPNet to learn concepts in a supervised manner like the CBM but with lesser annotated data. We use small auxiliary concept datasets with ~20 image patches per concepts to provide supervision for concept learning. We obtain concept embeddings by encoding the concept patches with the same encoder as the image encoder and optimise clustering objectives with these embeddings. The learned concept embeddings are used to calculate concept similarity scores on new images and make predictions based on the concepts present. The model pipeline is illustrated in the figure.
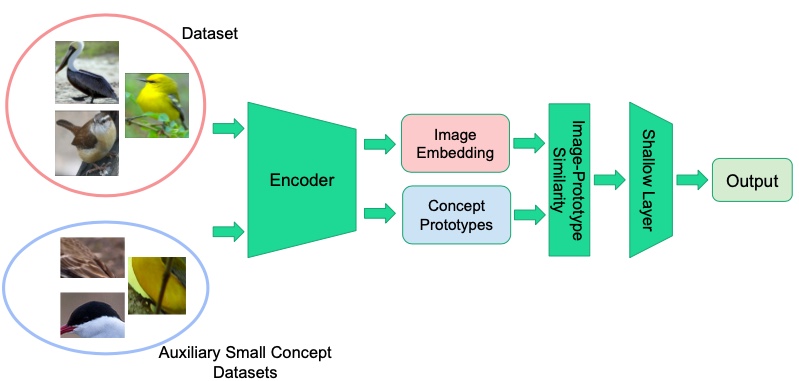
Our model achieved performance comparable to the other inherently interpretable models discussed (~70% on UCSD Birds Dataset). Notably, we achieved this performance with a much better data-efficiency (10-20 auxilliary concept images) with grounded and faithful concept explanations. The prototype similarity mechanism provides an intuitive way to visualise input image parts with respect to concept patches rather than binary labels given by the CBM. Visualising the input image and concept patches helps explain the similarity scores and interpret model decisions.

You can find the code for project here and refer to the report for details.